Kafka的message存储数据结构
replication-factor副本因子的解读
实际项目中我们可能在创建topic时没有设置好正确的replication-factor,导致kafka集群虽然是高可用的,但是该topic在有broker宕机时,可能发生无法使用的情况。topic一旦使用又不能轻易删除重建,因此动态增加副本因子就成为最终的选择。
说明:kafka 1.0版本配置文件默认没有default.replication.factor=x, 因此如果创建topic时,不指定–replication-factor 想, 默认副本因子为1. 我们可以在自己的server.properties中配置上常用的副本因子,省去手动调整。例如设置default.replication.factor=3, 详细内容可参考官方文档https://kafka.apache.org/documentation/#replication
原因分析:
假设我们有3个kafka broker分别brokerA、brokerB、brokerC.
当我们创建的topic有3个分区partition时并且replication-factor为1,基本上一个broker上一个分区。当一个broker宕机了,该topic就无法使用了,因为三个分区只有两个能用,
当我们创建的topic有3个分区partition时并且replication-factor为2时,可能分区数据分布情况是
brokerA, partiton0,partiton1,
brokerB, partiton1,partiton2
brokerC, partiton2,partiton0,
每个分区有一个副本,当其中一个broker宕机了,kafka集群还能完整凑出该topic的三个分区,例如当brokerA宕机了,可以通过brokerB和brokerC组合出topic的三个分区。
如何动态给已经创建的topic添加replication-factor?
可能很多人想使用kafka-topics.sh脚本,那么事情情况如何了?
[root@xszeree6p5z bin]# ./kafka-topics.sh –alter –topic yqtopic01 –zookeeper localhost:2181 –replication-factor 3
Option “[replication-factor]” can’t be used with option”[alter]”
Option Description
—— ———–
–alter Alter the number of partitions,
replica assignment, and/or
configuration for the topic.
–config <String: name=value> A topic configuration override for the
截图
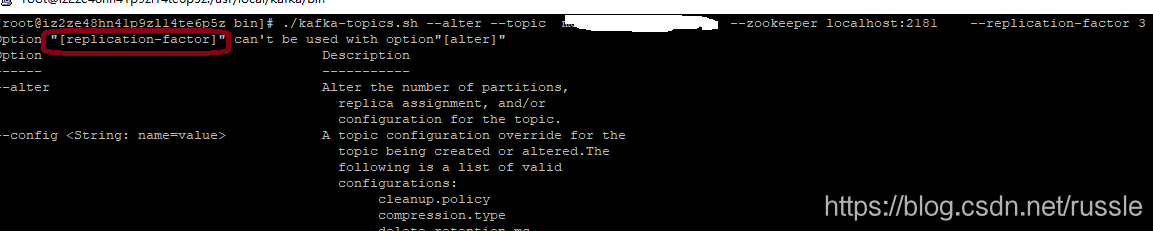
可以看出kafka-topics.sh不能用来增加副本因子replication-factor。实际应该使用kafka bin目录下面的kafka-reassign-partitions.sh。
a, 首先我们配置topic的副本,保存为json文件()
例如, 我们想把yqtopic01的部分设置为3,(我的kafka集群有3个broker,id分别为0,1,2), json文件名称为increase-replication-factor.json
{“version”:1,
“partitions”:[
{“topic”:“yqtopic01”,“partition”:0,“replicas”:[0,1,2]},
{“topic”:“yqtopic01”,“partition”:1,“replicas”:[0,1,2]},
{“topic”:“yqtopic01”,“partition”:2,“replicas”:[0,1,2]}
]}
b, 然后执行脚本
./kafka-reassign-partitions.sh -zookeeper 127.0.0.1:2181 –reassignment-json-file increase-replication-factor.json –execute
kafka-reassign-partitions.sh执行截图

我们可以通过执行
kafka-topics.sh –describe –zookeeper localhost:2181 –topic yqtopic01查看现在该topic的副本因子。
总结
所有文档官方文档最权威。https://kafka.apache.org/documentation/#basic_ops_increase_replication_factor
———————
作者:russle
来源:CSDN
原文:https://blog.csdn.net/russle/article/details/83421904
版权声明:本文为博主原创文章,转载请附上博文链接!
#引言
Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的。每个topic又可以分成几个不同的partition(每个topic有几个partition是在创建topic时指定的),每个partition存储一部分Message。借用官方的一张图,可以直观地看到topic和partition的关系。
在这里插入图片描述

partition是以文件的形式存储在文件系统中,比如,创建了一个名为page_visits的topic,其有5个partition,那么在Kafka的数据目录中(由配置文件中的log.dirs指定的)中就有这样5个目录:
page_visits-0, page_visits-1,page_visits-2,page_visits-3,page_visits-4
其命名规则为-,里面存储的分别就是这5个partition的数据。
接下来,本文将分析partition目录中的文件的存储格式和相关的代码所在的位置。
3.1、Partition的数据文件
Partition中的每条Message由offset来表示它在这个partition中的偏移量,这个offset不是该Message在partition数据文件中的实际存储位置,而是逻辑上一个值,它唯一确定了partition中的一条Message。因此,可以认为offset是partition中Message的id。partition中的每条Message包含了以下三个属性:
offset
MessageSize
data
其中offset为long型,MessageSize为int32,表示data有多大,data为message的具体内容。它的格式和Kafka通讯协议中介绍的MessageSet格式是一致。
Partition的数据文件则包含了若干条上述格式的Message,按offset由小到大排列在一起。它的实现类为FileMessageSet,类图如下:
在这里插入图片描述
它的主要方法如下:
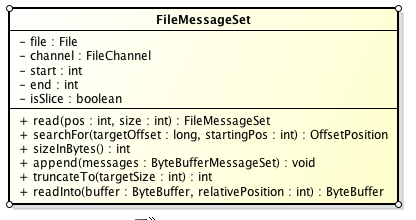
append: 把给定的ByteBufferMessageSet中的Message写入到这个数据文件中。
searchFor: 从指定的startingPosition开始搜索找到第一个Message其offset是大于或者等于指定的offset,并返回其在文件中的位置Position。它的实现方式是从startingPosition开始读取12个字节,分别是当前MessageSet的offset和size。如果当前offset小于指定的offset,那么将position向后移动LogOverHead+MessageSize(其中LogOverHead为offset+messagesize,为12个字节)。
read:准确名字应该是slice,它截取其中一部分返回一个新的FileMessageSet。它不保证截取的位置数据的完整性。
sizeInBytes: 表示这个FileMessageSet占有了多少字节的空间。
truncateTo: 把这个文件截断,这个方法不保证截断位置的Message的完整性。
readInto: 从指定的相对位置开始把文件的内容读取到对应的ByteBuffer中。
我们来思考一下,如果一个partition只有一个数据文件会怎么样?
新数据是添加在文件末尾(调用FileMessageSet的append方法),不论文件数据文件有多大,这个操作永远都是O(1)的。
查找某个offset的Message(调用FileMessageSet的searchFor方法)是顺序查找的。因此,如果数据文件很大的话,查找的效率就低。
那Kafka是如何解决查找效率的的问题呢?有两大法宝:1) 分段 2) 索引。
3.2、数据文件的分段
Kafka解决查询效率的手段之一是将数据文件分段,比如有100条Message,它们的offset是从0到99。假设将数据文件分成5段,第一段为0-19,第二段为20-39,以此类推,每段放在一个单独的数据文件里面,数据文件以该段中最小的offset命名。这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中。
3.3、为数据文件建索引
数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message了,但是这依然需要顺序扫描才能找到对应offset的Message。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。
索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引。索引包含两个部分(均为4个字节的数字),分别为相对offset和position。
相对offset:因为数据文件分段以后,每个数据文件的起始offset不为0,相对offset表示这条Message相对于其所属数据文件中最小的offset的大小。举例,分段后的一个数据文件的offset是从20开始,那么offset为25的Message在index文件中的相对offset就是25-20 = 5。存储相对offset可以减小索引文件占用的空间。
position,表示该条Message在数据文件中的绝对位置。只要打开文件并移动文件指针到这个position就可以读取对应的Message了。
index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
在Kafka中,索引文件的实现类为OffsetIndex,它的类图如下:
在这里插入图片描述
主要的方法有:
append方法,添加一对offset和position到index文件中,这里的offset将会被转成相对的offset。
lookup, 用二分查找的方式去查找小于或等于给定offset的最大的那个offset
小结
我们以几张图来总结一下Message是如何在Kafka中存储的,以及如何查找指定offset的Message的。

Message是按照topic来组织,每个topic可以分成多个的partition,比如:有5个partition的名为为page_visits的topic的目录结构为:
在这里插入图片描述
partition是分段的,每个段叫LogSegment,包括了一个数据文件和一个索引文件,下图是某个partition目录下的文件:
可以看到,这个partition有4个LogSegment。


展示是如何查找Message的。
比如:要查找绝对offset为7的Message:
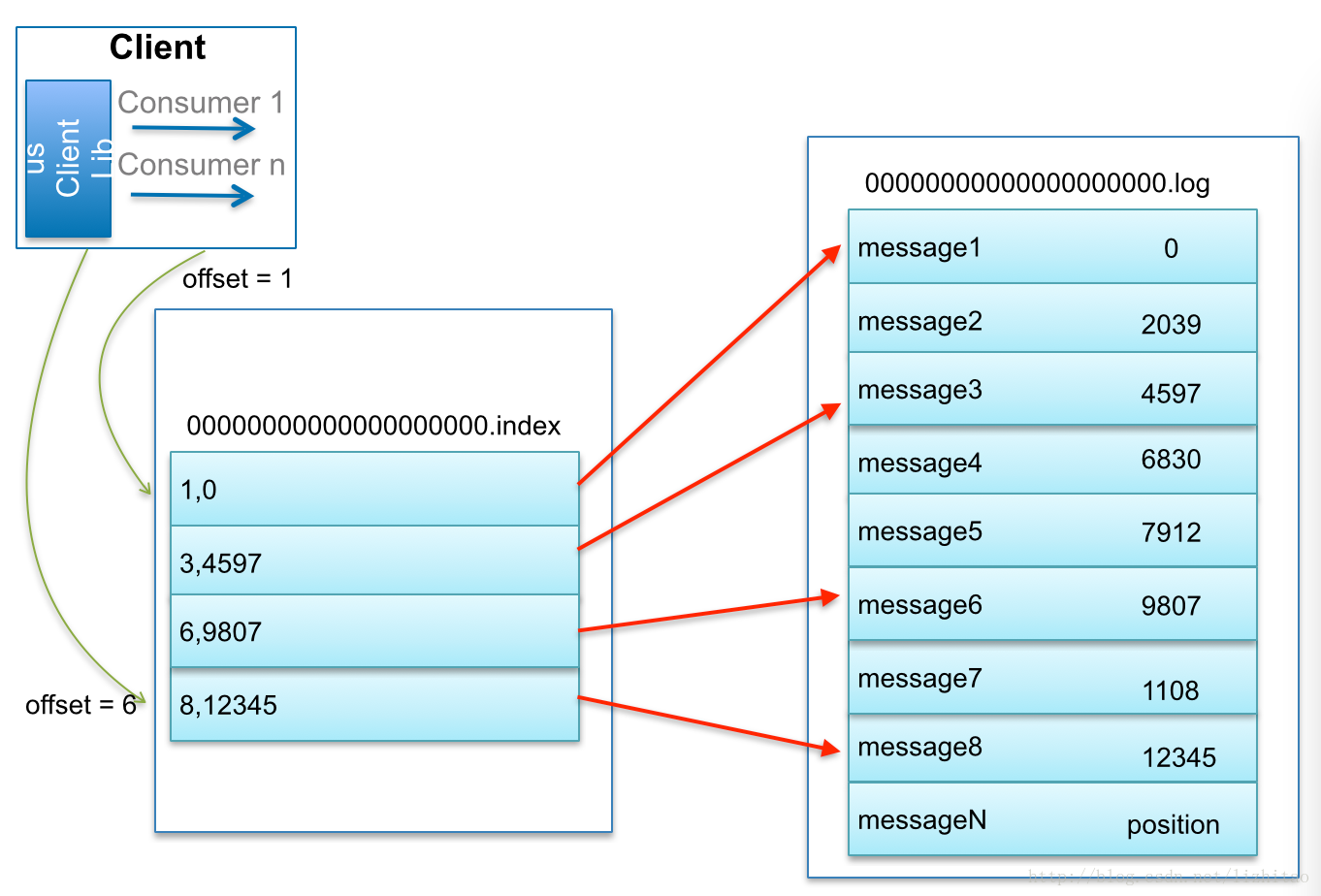
首先是用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。
打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
这套机制是建立在offset是有序的。索引文件被映射到内存中,所以查找的速度还是很快的。
一句话,Kafka的Message存储采用了分区(partition),分段(LogSegment)和稀疏索引这几个手段来达到了高效性。
转载请注明:SuperIT » Kafka的message存储数据结构





