用Docker在一台笔记本电脑上搭建一个具有10个节点7种角色的Hadoop集群(下)-搭建Hadoop集群
上篇:用Docker在一台笔记本电脑上搭建一个具有10个节点7种角色的Hadoop集群(上)-快速上手Docker
上篇介绍了快速上手Docker部分,下面接着介绍搭建Hadoop集群部分。
六、搭建Hadoop伪分布模式
我们先用前面创建的这个容器来搭建Hadoop伪分布模式做测试,测试成功后再搭建完全分布式集群。
1.SSH
这个centos容器可以看做是一个非常精简的系统,很多功能没有,需要自己安装。
Hadoop需要SSH,但容器没有自带,需要我们安装。
①安装SSH
# yum -y install openssh-clients openssh-server


②生成3个key文件
# ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key 一路回车
# ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key 一路回车
# ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key 一路回车

③启动sshd
# /usr/sbin/sshd

④修改root密码
因为默认的密码不知道,我们重新设置一下。
# passwd root

⑤设置ssh免密登录到本机
# ssh-keygen 一路回车

# ssh-copy-id localhost 输入密码

# ssh localhost
免密登录成功

# exit
退回到刚才的shell中。

2.which
运行hadoop需要which命令,同样容器没有自带,需要我们安装。
# yum -y install which


3.文件复制
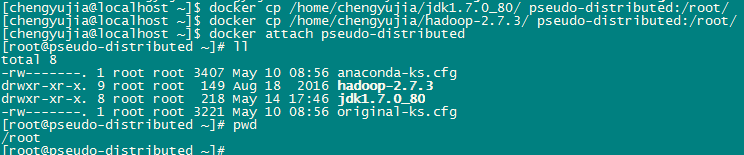
下面我们将已经提前准备好的JDK和Hadoop从宿主机上复制到容器中。注意,复制操作要在Docker宿主机上进行。
$ docker cp /home/chengyujia/jdk1.7.0_80/ pseudo-distributed:/root/ $ docker cp /home/chengyujia/hadoop-2.7.3/ pseudo-distributed:/root/
在容器中可以看到JDK和Hadoop已复制到位。
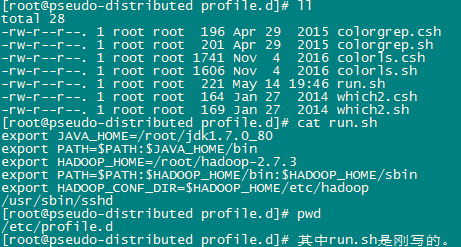
4.配置环境变量并在容器启动时启动sshd
在/etc/profile.d中新建一个run.sh文件
在run.sh文件中写入下面6行内容:

export JAVA_HOME=/root/jdk1.7.0_80 export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/root/hadoop-2.7.3 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop /usr/sbin/sshd
用exit命令退出容器,重新启动并进入容器,上面配置的环境变量会生效,sshd也会启动。

5.hadoop伪分布式配置
①配置hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}中的${JAVA_HOME}替换为具体路径,这里为export JAVA_HOME=/root/jdk1.7.0_80。
②配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
③配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
④配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
⑤配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6.启动伪分布集群并运行wordcount示例程序
①准备测试数据
新建一个input文件夹,在这个文件夹中新建一个test.txt文件,里面随便写点单词,然后将该文件多复制几份,我这里复制了5份。

②格式化namenode
# hdfs namenode -format
③启动HDFS
# start-dfs.sh
④启动YARN
# start-yarn.sh
⑤查看相关进程是否都启动
# jps
如有以下5个进程,说明启动成功。
DataNode NodeManager NameNode SecondaryNameNode ResourceManager
⑥将测试数据复制到HDFS中
# hdfs dfs -put /root/input /

⑦运行wordcount示例程序
# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input /output
⑧查看输出结果
# hdfs dfs -cat /output/part-r-00000

从截图可以看出输出正确。伪分布式测试完毕。
七、搭建Hadoop完全分布式集群
1.集群规划
1个NameNode节点(主节点,默认节点,master节点) 1个SecondaryNameNode节点 1个ResourceManager节点 1个JobHistory节点 5个Slave节点 1个Client节点
其中Slave节点包含DataNode和NodeManager两种角色。
Client节点是用来操作的节点,所有操作都尽量在这个节点上进行。
以上共10个节点,7种角色。
2.将上面的伪分布式容器打包成镜像
理论上,我们只要将上面的伪分布式容器复制10份,然后改改配置文件就行了。但是Docker容器不能直接复制,需要先打包成镜像,然后用这个镜像生成10个新的容器。
命令如下:
$ docker commit -a "成宇佳" -m "Hadoop在centos上搭建的伪分布模式。" pseudo-distributed hadoop-centos:v1
-a 表示作者。
-m 表示对该镜像的说明。
pseudo-distributed 被打包容器的名称
hadoop-centos:v1 生成镜像的名称及版本
需要知道的是,因为这个被打包的容器是通过centos镜像创建的,所以由该容器打包成的新镜像也包含了centos镜像。

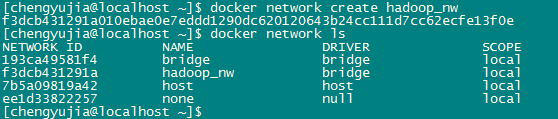
3.创建网络
$ docker network create hadoop_nw
这里新建了一个叫hadoop_nw的网络,后面将10个Hadoop节点容器都加入到该网络,就能相互间通信了。而且不需要配置hosts文件,直接通过容器名称即可访问。
$ docker network ls
通过该命令可以查看所有的网络,除了我们刚创建的hadoop_nw网络,其它都是安装Docker时自动生成的,在本文中不用管它们。
4.用新生成的镜像创建10个容器
$ docker run -itd --privileged --network hadoop_nw -h namenode --name namenode -p 50070:50070 hadoop-centos:v1 $ docker run -itd --privileged --network hadoop_nw -h secondarynamenode --name secondarynamenode hadoop-centos:v1 $ docker run -itd --privileged --network hadoop_nw -h resourcemanager --name resourcemanager -p 8088:8088 hadoop-centos:v1 $ docker run -itd --privileged --network hadoop_nw -h jobhistory --name jobhistory -p 19888:19888 hadoop-centos:v1 $ docker run -itd --privileged --network hadoop_nw -h slave1 --name slave1 hadoop-centos:v1 $ docker run -itd --privileged --network hadoop_nw -h slave2 --name slave2 hadoop-centos:v1 $ docker run -itd --privileged --network hadoop_nw -h slave3 --name slave3 hadoop-centos:v1 $ docker run -itd --privileged --network hadoop_nw -h slave4 --name slave4 hadoop-centos:v1 $ docker run -itd --privileged --network hadoop_nw -h slave5 --name slave5 hadoop-centos:v1 $ docker run -itd --privileged --network hadoop_nw -h client --name client hadoop-centos:v1
注意要加 –privileged
-itd 表示打开终端但不进入
–network 表示加入到哪个网络
-p 表示端口映射
从上面可以看到namenode、resourcemanager和jobhistory这3个节点做了端口映射。端口映射的作用是将Docker宿主机的某个端口映射到容器的某个端口上,这样我们通过访问Docker宿主机的这个端口就能间接访问到相应的容器端口了。就像从外网访问内网中的某台机器一样。我们在后面通过浏览器查看集群信息的时候会用到。

5.修改Hadoop配置文件
我们在client节点修改,然后复制到其它节点。
①配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-2.7.3/data</value>
</property>
</configuration>
②配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>secondarynamenode:50090</value>
</property>
</configuration>
③配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>jobhistory:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>jobhistory:19888</value>
</property>
</configuration>
④配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>resourcemanager</value>
</property>
</configuration>
⑤配置slaves文件
#localhost slave1 slave2 slave3 slave4 slave5
6.配置节点间SSH免密登录
在client节点执行:
# ssh-copy-id namenode # ssh-copy-id secondarynamenode # ssh-copy-id resourcemanager # ssh-copy-id jobhistory # ssh-copy-id slave1 # ssh-copy-id slave2 # ssh-copy-id slave3 # ssh-copy-id slave4 # ssh-copy-id slave5
在resourcemanager节点执行:
# ssh-copy-id slave1 # ssh-copy-id slave2 # ssh-copy-id slave3 # ssh-copy-id slave4 # ssh-copy-id slave5
7.复制配置文件到所有节点
在client节点执行:
# scp -r $HADOOP_HOME/etc/hadoop namenode:$HADOOP_HOME/etc # scp -r $HADOOP_HOME/etc/hadoop secondarynamenode:$HADOOP_HOME/etc # scp -r $HADOOP_HOME/etc/hadoop resourcemanager:$HADOOP_HOME/etc # scp -r $HADOOP_HOME/etc/hadoop jobhistory:$HADOOP_HOME/etc # scp -r $HADOOP_HOME/etc/hadoop slave1:$HADOOP_HOME/etc # scp -r $HADOOP_HOME/etc/hadoop slave2:$HADOOP_HOME/etc # scp -r $HADOOP_HOME/etc/hadoop slave3:$HADOOP_HOME/etc # scp -r $HADOOP_HOME/etc/hadoop slave4:$HADOOP_HOME/etc # scp -r $HADOOP_HOME/etc/hadoop slave5:$HADOOP_HOME/etc
8.启动Hadoop集群
在client节点执行:
①格式化namenode
# ssh namenode "hdfs namenode -format"
②启动HDFS集群
# start-dfs.sh
③启动YARN集群
# ssh resourcemanager "start-yarn.sh"
④启动JobHistory
# ssh jobhistory "mr-jobhistory-daemon.sh --config $HADOOP_CONF_DIR start historyserver"
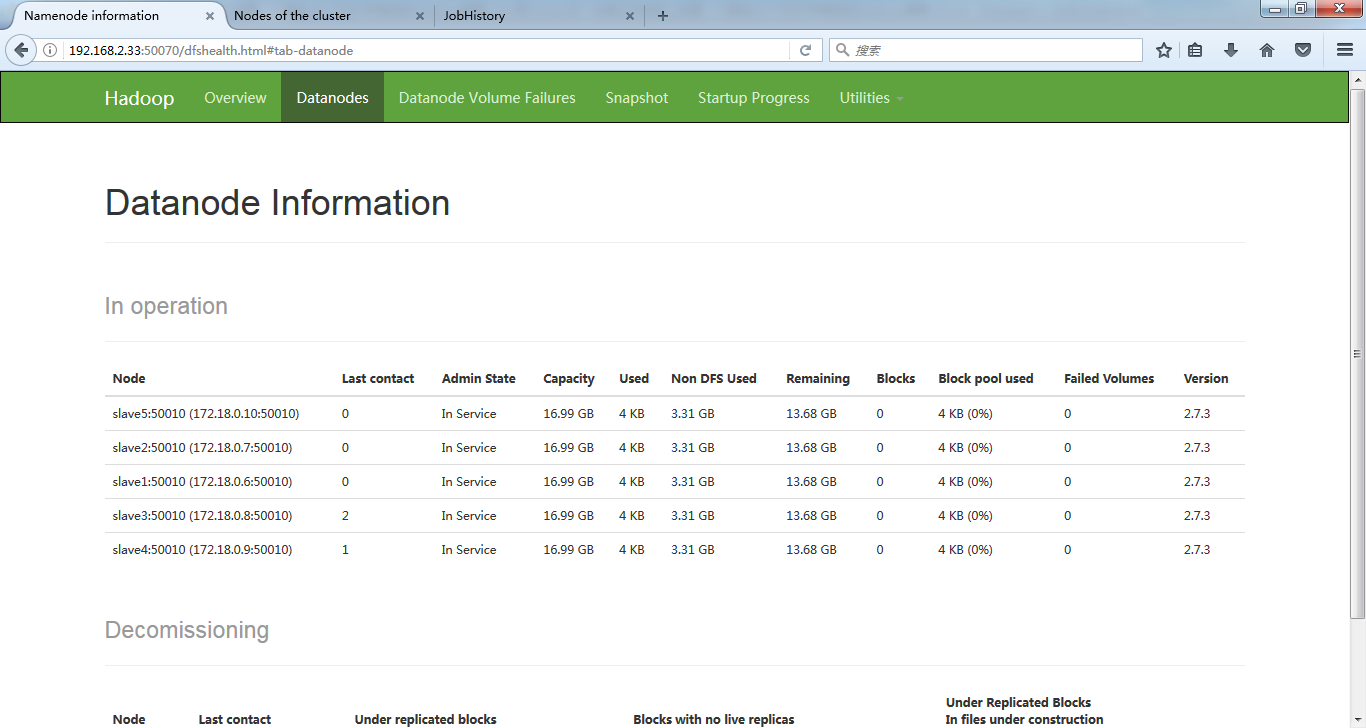
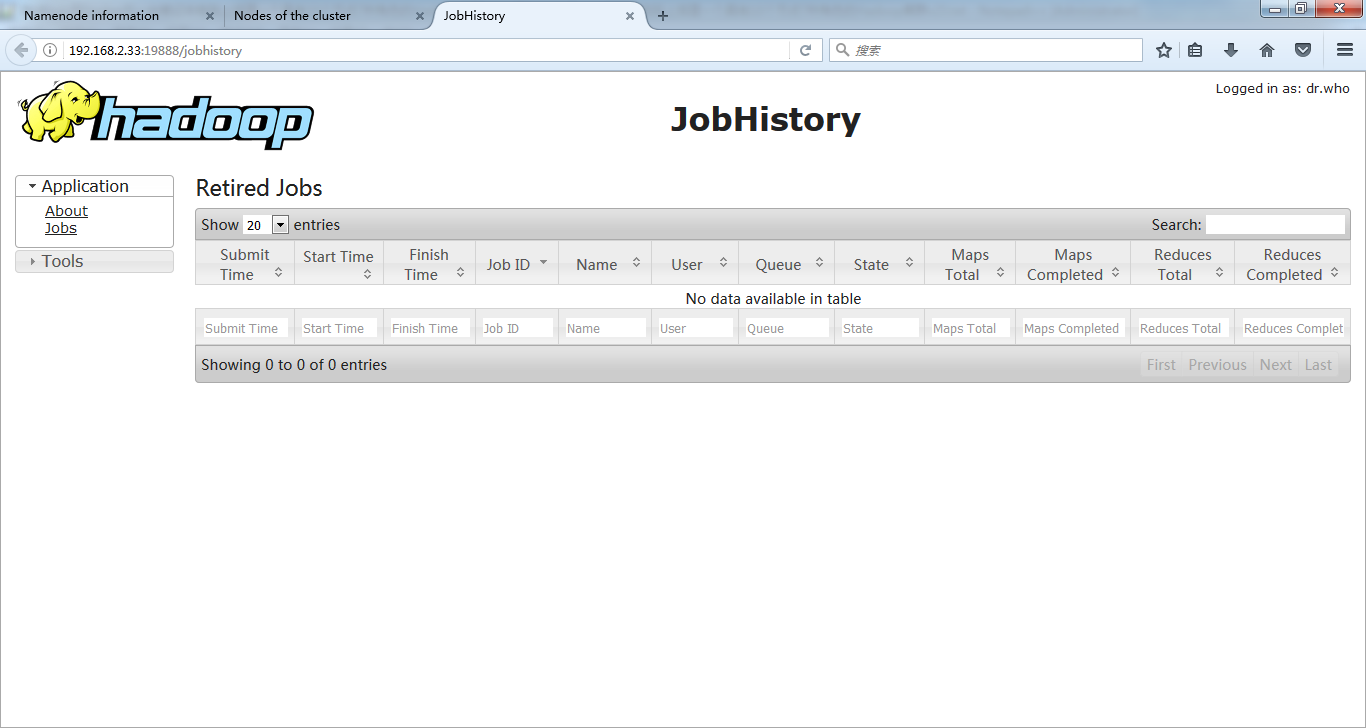
9.在浏览器中查看集群信息
由于指定过相应容器的端口映射,我在我的Windows上用浏览器访问Docker宿主机相应的端口就能访问到容器。
HDFS http://Docker宿主机IP:50070/ YARN http://Docker宿主机IP:8088/ jobhistory http://Docker宿主机IP:19888/
从web上可以看到集群正常:

10.运行wordcount示例程序
①将测试数据复制到HDFS中
# hdfs dfs -put /root/input /

②运行wordcount示例程序
# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input /output
③查看输出结果
# hdfs dfs -cat /output/part-r-00000

从截图可以看到输出结果正确。完全分布式集群搭建完毕。
参考资料
写本文时参考了很多网上的资料,在此一并表示感谢!
docker 安装hadoop
http://www.cnblogs.com/liqiu/p/4164406.html
docker安装hadoop集群
http://www.cnblogs.com/songfy/p/4716431.html
Docker搭建hadoop集群
http://www.cnblogs.com/liuyifeng/p/5383076.html
基于Docker快速搭建多节点Hadoop集群
http://dockone.io/article/395
基于Docker搭建Hadoop集群之升级版
http://kiwenlau.com/2016/06/12/160612-hadoop-cluster-docker-update/
使用docker搭建hadoop分布式集群
http://blog.csdn.net/xu470438000/article/details/50512442
使用Docker在本地搭建Hadoop分布式集群
http://tashan10.com/yong-dockerda-jian-hadoopwei-fen-bu-shi-ji-qun/
Docker实战(十四):Docker安装Hadoop环境
http://blog.csdn.net/birdben/article/details/51724126
从 0 开始使用 Docker 快速搭建 Hadoop 集群环境
http://www.jianshu.com/p/b75f8bc9346d
本文结束,谢谢大家!
博客主页:http://www.cnblogs.com/chengyujia/
欢迎转载,但请保留作者和本文链接,谢谢!
欢迎在下面的评论区与我交流。
转载请注明:SuperIT » 用Docker在一台笔记本电脑上搭建一个具有10个节点7种角色的Hadoop集群(下)-搭建Hadoop集群





